title: Claude Opus 4.7 Released: What SaaS Founders and Indie Builders Actually Need to Know slug: claude-opus-47-saa-founders-indie-builders-guide meta_description: Claude Opus 4.7 dropped today with a 64.3% SWE-bench Pro score, a new xhigh effort level, and task budgets for cost control. Here's the honest breakdown for SaaS founders and indie builders. target_keywords: Claude Opus 4.7, SaaS founders, indie developers, AI coding tools, SWE-bench Pro, Claude Code, task budgets, xhigh effort level published_at: 2026-04-17 cover_image_url: https://f003.backblazeb2.com/file/digital-upstream/blog/claude-opus-47-saa-founders-indie-builders-guide/digital-upstream-claude-opus-47-ai-coding-update-thumbnail.jpg secondary_image_urls:
- https://f003.backblazeb2.com/file/digital-upstream/blog/claude-opus-47-saa-founders-indie-builders-guide/digital-upstream-claude-opus-47-swe-bench-comparison.png
- https://f003.backblazeb2.com/file/digital-upstream/blog/claude-opus-47-saa-founders-indie-builders-guide/digital-upstream-claude-opus-47-task-budgets.png video_url: https://f003.backblazeb2.com/file/digital-upstream/blog/claude-opus-47-saa-founders-indie-builders-guide/claude-opus-47-saa-founders-indie-builders-guide-animation.mp4
Claude Opus 4.7 dropped today. Skip the press release — here's what actually changed for the developers shipping products right now.
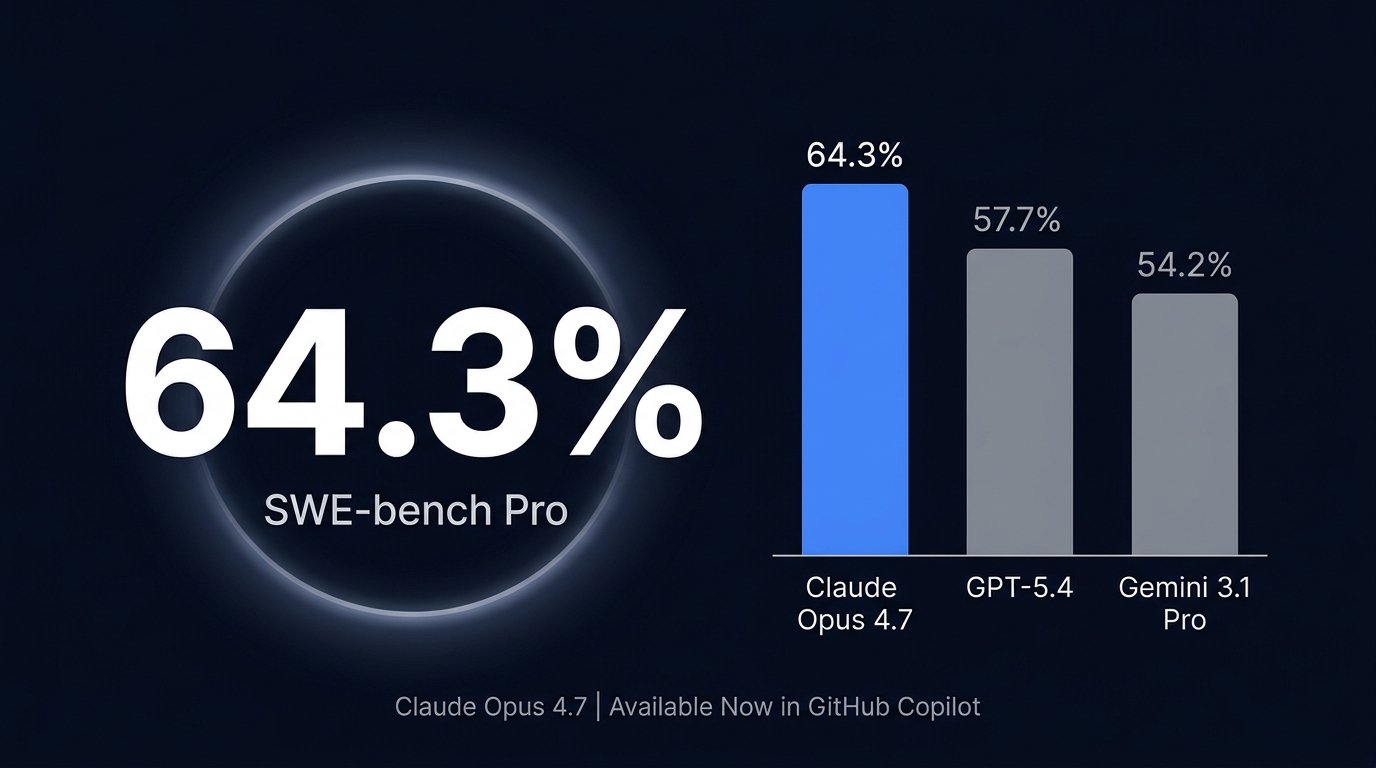
Anthropic's latest flagship model posted a 64.3% score on SWE-bench Pro, the industry-standard benchmark for real software engineering tasks. That's not a marginal improvement. GPT-5.4 hit 57.7%. Gemini 3.1 Pro came in at 54.2%. On this particular test, Opus 4.7 didn't just compete — it widened the gap.
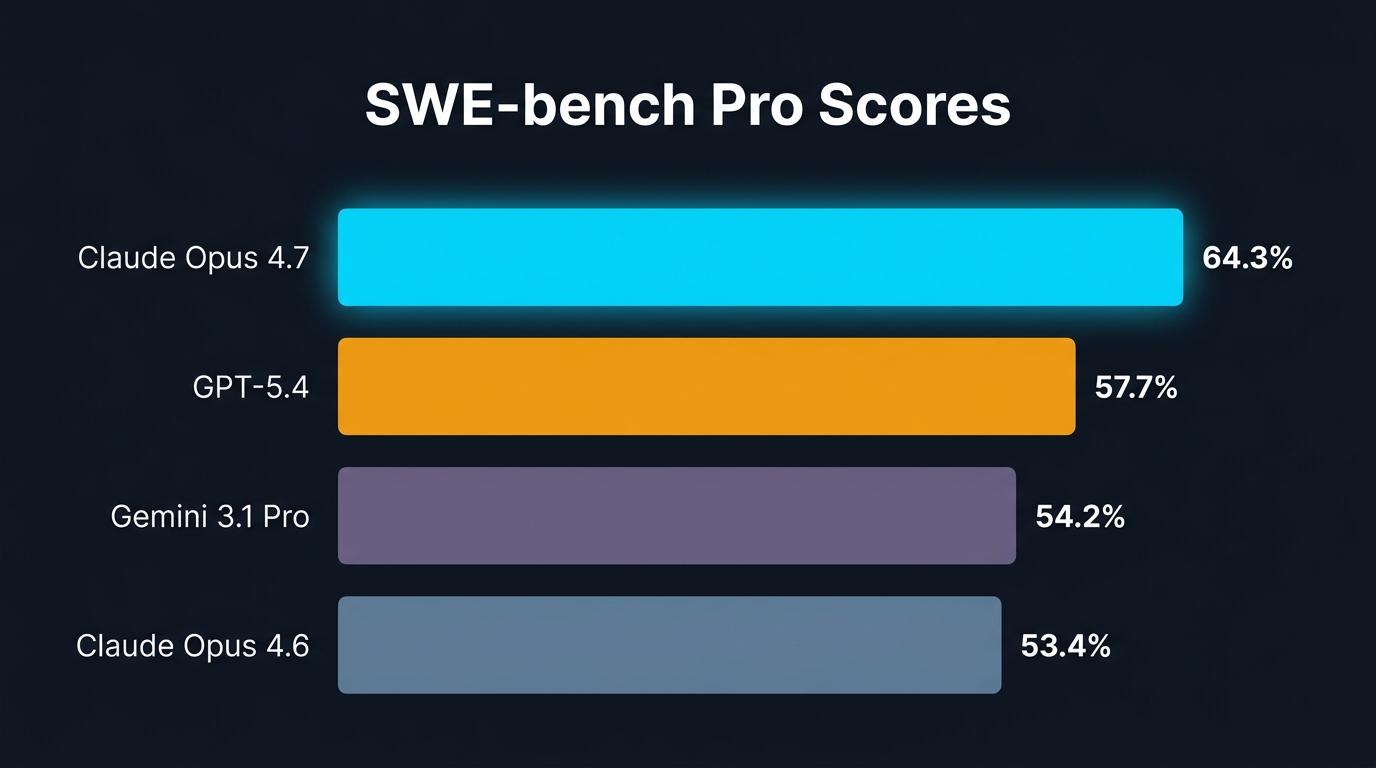
The number behind the number: Anthropic reports a 13% improvement on a 93-task coding benchmark compared to Opus 4.6. More tellingly, Opus 4.7 solved four tasks that neither Opus 4.6 nor Sonnet 4.6 could crack. If you've been watching an AI coding assistant bang its head against the same bug for the past two weeks, that gap just became relevant.
What got better
The SWE-bench Pro score is the headline, but it's not the whole story. Three specific improvements matter for builders running AI-assisted workflows:
xhigh effort level. Every model has a reasoning budget — how hard it thinks before responding. Opus 4.7 introduces a new "xhigh" setting that goes beyond what Opus 4.6 offered. More thorough reasoning at the cost of more tokens. For complex multi-file refactors or architectural decisions, this is the knob developers have been asking for.
3.75MP vision upgrade. Higher image resolution means better screenshot analysis, UI review, and document parsing. If you're automating anything involving visual input, the vision upgrade compounds over time.
Task budgets (beta). This one flies under the radar but it's the most practical addition for indie builders managing API costs. You can now set token or spend caps per task — Claude stops when it hits the limit rather than running up a bill on a runaway loop. For builders who treat AI as a per-feature cost line item, this is a meaningful risk control.

The GitHub Copilot angle
Opus 4.7 is now available in GitHub Copilot. GitHub's own early testing describes "stronger multi-step task performance and more reliable agentic execution." No configuration changes required if you're already a Copilot user — your existing workflow just got a quality upgrade. For founders who rely on Copilot as their primary coding assistant, this is a free, immediate improvement.
The context regression nobody is talking about
One nuance worth flagging: Reddit community testing suggests Opus 4.7 shows regressions on long-context retrieval tasks compared to Opus 4.6. It's better at reasoning and traversal, worse at flat lookups. If you're working with very large codebases and relying on the model to locate specific symbols or definitions, test before you trust. This isn't a dealbreaker — it's a configuration call.
The price didn't move
Opus 4.7 costs the same as Opus 4.6: five dollars input, twenty-five dollars output per million tokens. Anthropic held pricing in a market where costs typically fall. Prompt caching still delivers up to 90% savings on repeated contexts, and batch processing still offers 50% off for async workloads. For builders who have already optimized their prompts around caching, the economics remain favorable.
What this means for your stack
If you're choosing a model for an AI-assisted coding workflow — whether that's GitHub Copilot, a Cursor custom model, a CLI tool wired to the Claude API, or an agentic pipeline you're building — Opus 4.7 is now the benchmark to beat on software engineering tasks. The 64.3% SWE-bench Pro number isn't abstract. It's the difference between an AI that helps you ship and one that gives you homework.
The gap is real. The price is stable. The upgrade is free if you're already in the ecosystem.
Start using it through the Claude API, or if you're already on Copilot, the updated model is live now — no action required on your end beyond pulling the latest version.